After a long 12 months of pouring my soul into it, my book, Data Analysis with R, was finally published. After the requisite 2-4 day breather, I started thinking about how I was going to get back into the swing of regular blog posts and decided that the easier and softer way is to cannibalize and expand on an example in the book.
In the chapter “Sources of Data” I show how to consume web data of different formats in R. The motivating example is to build a simple recommendation system that uses user-supplied “tags” (genres/labels) submitted to Last.fm and MusicBrainz to quantify musical artist “similarity”. The example in the book stops at the construction and sorting of the similarity matrix but, in this post, we’re going to make a really fly D3 visualization of the musical similarity network and provide recommendations in the tooltips. The code, including the Javascript and HTML, I used for this post was hastily thrown into a git repo and is available here. If you’re uninterested in the detailed methodology, I suggest you skip to the section labeled “Outcome”.
Methodology
Although in the book tags from both Last.fm and MusicBrainz are used, we’ll just be using Last.fm here. (In additional contrast to the book, the code here is, as you might imagine, substantially faster-paced.)
The first step is to make a character vector of all the artists that you’d like to be included. If you were building a real system, you’d probably want all Last.fm artists. Since we’re not, I just used 70 of my most played artists on my Last.fm. Since I got the list straight from the source, I didn’t have to worry that any of the API requests would return “No Artist Found”.
The following is a function that takes an artist and returns the properly formatted Last.fm API call to get the tags in JSON format.
1 | create_artist_query_url_lfm <- function(artist_name){ |
This is an example of the JSON payload from my favorite merengue artist.
We only want the tag names–curiously, attempts to factor in degree of tag fit (the “count” attribute) resulted in (what I interpreted as) substantially poorer recommendations.
The following is a function that will return a vector of all the tags.
1 | library(jsonlite) |
Since the above function is referentially transparent, and it involves using resources that aren’t yours, it’s a good idea to memoize the function so that if you (accidentally or otherwise) call the function with the same artist, the function will return the cached result instead of making the web request again. This can be achieved quite easily with the memoise package.
1 | library(memoise) |
To get the tags from all the artists in our custom ARTIST_LIST vector..
1 | artists_tags <- sapply(ARTIST_LIST, mem_get_tag_frame_lfm) |
To get a list of all pairs of artists to compute the similarity for, we can use the combn function to create a 2 by 2,415 character matrix of all possible combinations (choose 2). Let’s get that into a 2,415 by 2 data.frame with the name “artist1” and “artist2”…
1 | cmbs <- combn(ARTIST_LIST, 2) |
The similarity metric we’ll be using is simple as all get-out: the Jaccard index. Assuming we put the tags from both artists into two sets, it is the cardinality of the sets’ intersection divided by the sets’ union…
1 | jaccard_index <- function(tags1, tags2){ |
Now we’ve added a new column to our previously 2,415 by 2 data.frame, “similarity” that contains the Jaccard index.
Our D3 visualization expects a JSON with two top level attributes: “nodes” and “links”. The “nodes” attribute is an array of x number of 5 key-value pairs (where x is the number of nodes). The 5 keys are “name” (the name of the artist) “group” (a number that affects the coloring of the node in the visualization that we will be setting to “1”), and “first”, “second”, and “third”, which are the top 3 most similar artists and will serve as the recommendations that pop-up in a tool-tip when you mouse over an artist node in the visualization.
This is some code to get the top 3 most similar artists. It takes the 2,415 by 3 comparisons data.frame, the number of “most similar artists” to return, an artist, and an arbitrary threshold for “similar-ness” as arguments. Any similarity below this threshold will not be considered a viable recommendation.
1 | library(dplyr) |
The inner ifelse clause has to handle the fact that the “similar” artist can be in the first column or the second column. The outer ifelse returns “None” for every similarity value that is not above the threshold.
Let’s make the data.frame that will serve as the “nodes” attribute in the final JSON…
1 | nodes <- sapply(ARTIST_LIST, function(x) get_top_n(comparisons, 3, x, 0.25)) |
For the other top-level JSON attribute, “links”, we need an array of y number of 5 key-value pairs where y is the number of sufficiently strong similarities between the artists. The 5 keys are “node1” (the name of the first artist), “source” (the 0-indexed index of the artist with respect to the array in the “nodes” attribute), “node2” (the name of the second artist), “target” (the index of the second artist) and “weight”, which is the degree of similarity between the two artists; this will translate into thicker “edges” in the similarity graph.
1 | # find the 0-indexed index |
Finally, we can create the properly formatted JSON and send it to the file “artists.json” thusly…
1 | object <- list("nodes"=nodes, "links"=strong_links) |
Outcome
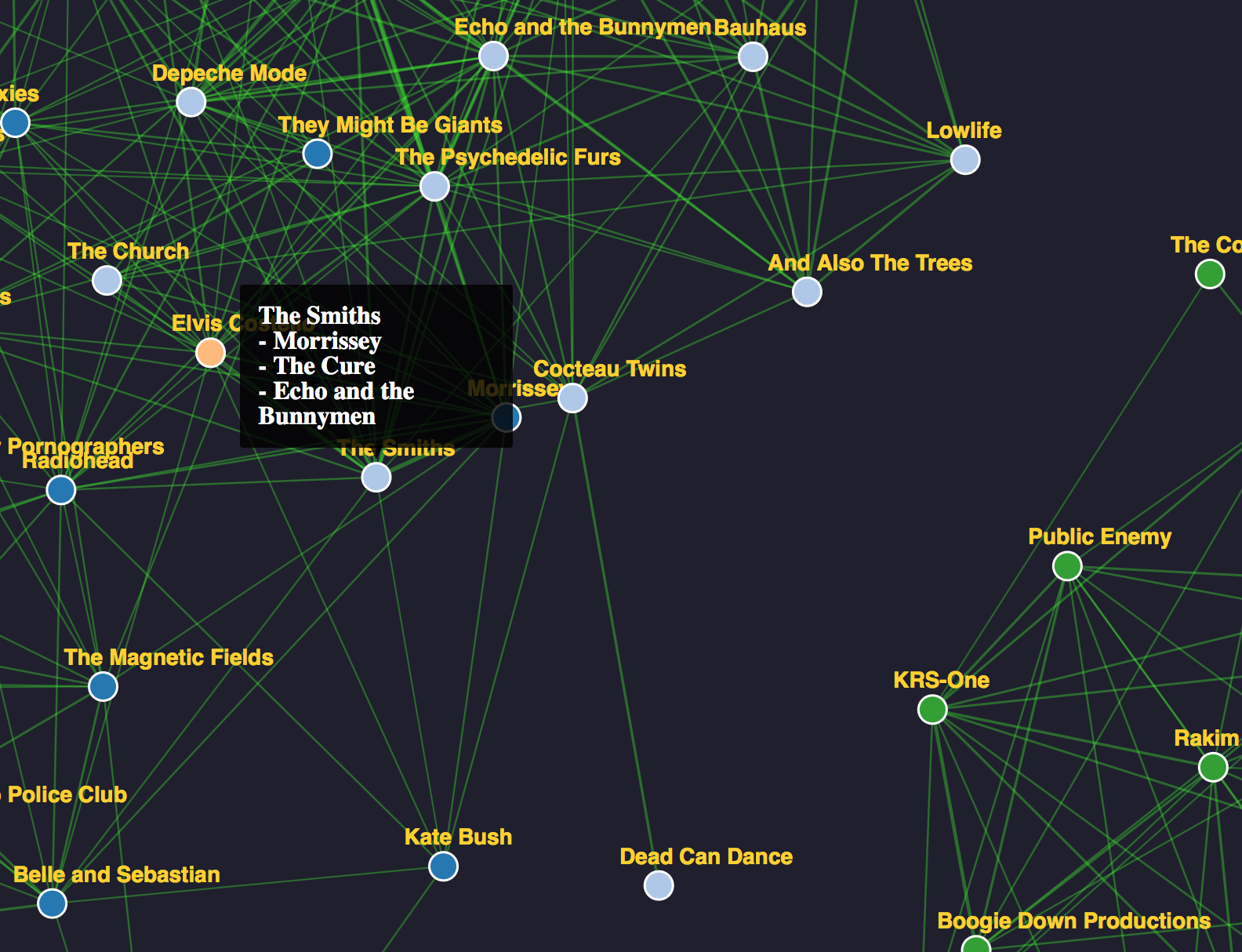
Using “artists.json” and the “index.html” that can be found here, the similarity graph looks a little like this. (Make sure you scroll to see the whole thing.)
For illustrative purposes, I pre-labeled the artists’ “group” with labels that correspond to what I view as the artist’s primary genre. This is why the nodes in the linked visualization have different colors. Note that, independently, the genres that I indicated tend to cluster together in the network. For example, Reggae (light green), Hip-Hop (green), and Punk (orange) all form almost completely connected graphs, though unconnected to each other (disjoint subgraphs). Indie rock (blue), post-punk (light blue) and classic rock (light orange) together form a rather tightly-connected subgraph. Curiously, the Sex Pistols (that I labeled “Punk”) are not part of the Punk cluster but part of the Indie-rock/post-punk/classic-rock component. There are three orphan nodes (no edges), “Johann Sebastian Bach”, “P:ano“, and “No Kids“. Bach is orphaned because he’s the only Baroque artist in my top 70 artists :( –P:ano and No Kids are obscure… you’ve probably never heard of them.
The recommendations, prima facie, appear to be on point. For example, without direct knowledge of association, “KRS-One” recommends “Boogie Down Productions” (the group that KRS-One comes from) most highly. Similarly, “The Smiths” and “Morrissey” recommend each other, and “De La Soul” and “A Tribe Called Quest” (part of a positive, Afrocentric hip-hop collective known as the Native Tongues together with Queen Latifah, et al.) recommend each other.
Appropriately, Joy Division and New Order, whose Jaccard index of band members is 0.6 but whose music style is somewhat distinct, don’t recommend each other. Lastly, subgenred artists appear to recommend other artists in the subgenre. For example, goth band “The Sisters of Mercy” appropriately recommends other goth-esque bands “Bauhaus”, “And Also The Trees”, and “Joy Division”.
Afterword
Using this similarity measure to drive recommendations seems successful. It should be noted, though, that my ability to assess the effectiveness of using the Jaccard index as the sole arbiter of musical similarity is hampered; judging an algorithm on the basis that the system recommends other bands that I necessarily like is prejudicial, to say the least.
This stands even if the system makes good theoretical sense. This still stands even if the system, quite independently, indicates that associated acts—that are objectively and incontrovertibly similar—are good recommendations.
This raises a larger question on how to accurately measure the effectiveness of recommender systems; do you tell people what they want to hear, or do you pledge allegiance to a particular theoretical interpretation of similarity? If it’s the latter, how do you iterate and improve the system? If it’s the former, is your only criterion for success positive user-provided feedback?