In a TODO previous post, we demonstrated that ridge regression (a form of regularized linear regression that attempts to shrink the beta coefficients toward zero) can be super-effective at combating overfitting and lead to a greatly more generalizable model. This approach to regularization used penalized maximum likelihood estimation (for which we used the amazing glmnet package). There is, however, another approach… an equivalent approach… but one that allows us greater flexibility in model construction and lends itself more easily to an intuitive interpretation of the uncertainty of our beta coefficient estimates. I’m speaking, of course, of the bayesian approach.
As it turns out, careful selection of the type and shape of our prior distributions with respect to the coefficients can mimic different types of frequentist linear model regularization. For ridge regression, we use normal priors of varying width.
Though it can be shown analytically that shifting the width of normal priors on the beta coefficients is equivalent to L2 penalized maximum likelihood estimation, the math is scary and hard to follow. In this post, we are going to be taking a computational approach to demonstrating the equivalence of the bayesian approach and ridge regression.
This post is going to be a part of a multi-post series investigating other bayesian approaches to linear model regularization including lasso regression facsimiles and hybrid approaches.
mtcars
We are going to be using the venerable mtcars dataset for this demonstration because (a) it’s multicollinearity and high number of potential predictors relative to its sample size lends itself fairly well to ridge regression, and (b) we used it in the TODO elastic net blog post :)
Before you lose interest… here! have a figure! An explanation will follow.
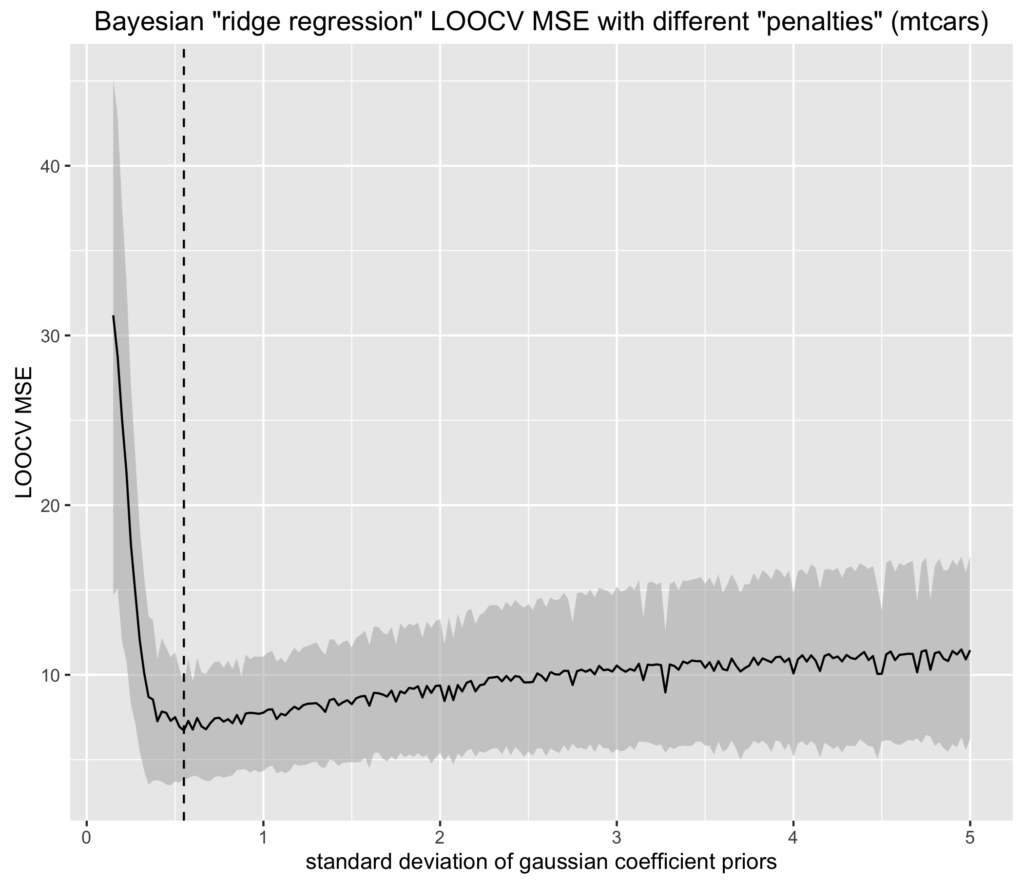
After scaling the predictor variables to be 0-centered and have a standard deviation of 1, I described a model predicting mpg using all available predictors and placed normal priors on the beta coefficients with a standard deviation for each value from 0.05 to 5 (by 0.025). To fit the model, instead of MCMC estimation via JAGS or Stan, I used quadratic approximation performed by the awesome rethinking package written by Richard McElreath written for his excellent book, Statistical Rethinking. Quadratic approximation uses an optimization algorithm to find the maximum a priori (MAP) point of the posterior distribution and approximates the rest of the posterior with a normal distribution about the MAP estimate. I use this method chiefly because as long as it took to run these simulations using quadratic approximation, it would have taken many orders of magnitude longer to use MCMC. Various spot checks confirmed that the quadratic approximation was comparable to the posterior as told by Stan.
As you can see from the figure, as the prior on the coefficients gets tighter, the model performance (as measured by the leave-one-out cross-validated mean squared error) improves—at least until the priors become too strong to be influenced sufficiently by the evidence. The ribbon about the MSE is the 95% credible interval (using a normal likelihood). I know, I know… it’s pretty damn wide.
The dashed vertical line is at the prior width that minimizes the LOOCV MSE. The minimum MSE is, for all practical purposes, identical to that of the highest performing ridge regression model using glmnet. This is good.
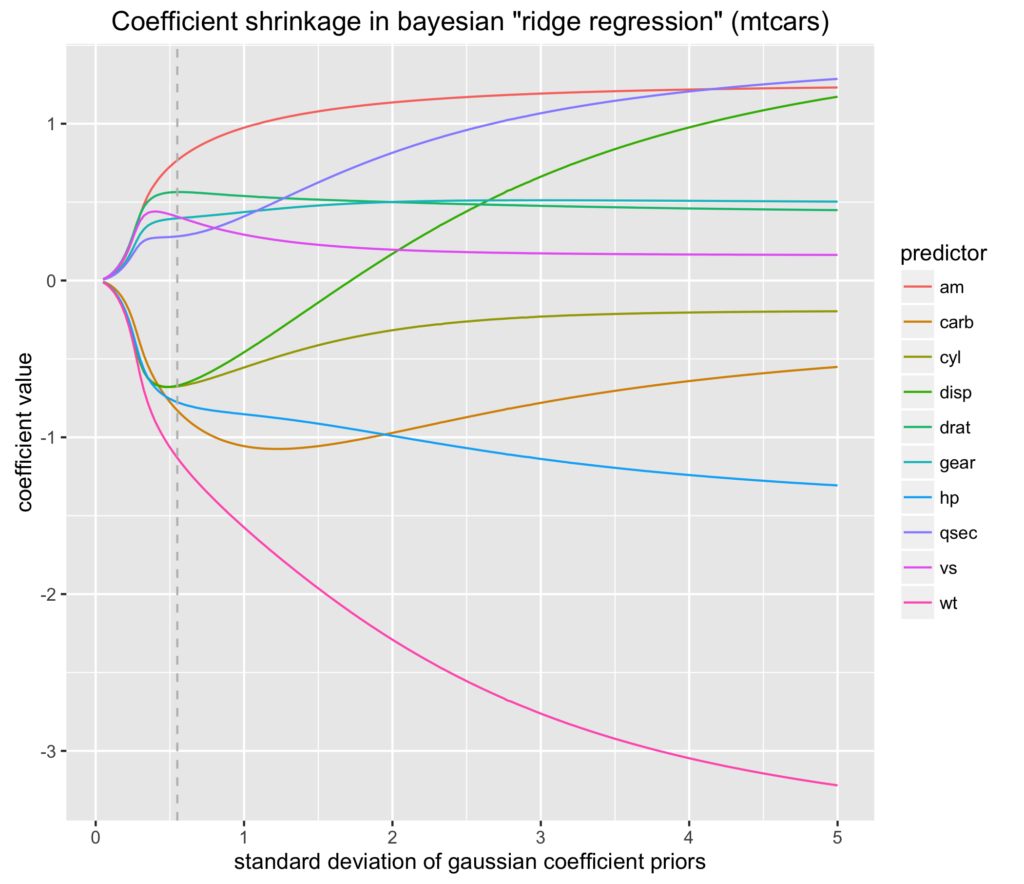
Another really fun thing to do with the results is to visualize the movement of the beta coefficient estimates and different penalties. The figure below depicts this. Again, the dashed vertical line is the highest performing prior width.
One last thing: we’ve heretofore only demonstrated that the bayesian approach can perform as well as the L2 penalized MLE… but it’s conceivable that it achieves this by finding a completely different coefficient vector. The figure below shows the same figure as above but I overlaid the coefficient estimates (for each predictor) of the top-performing glmnet model. These are shown as the dashed colored horizontal lines.
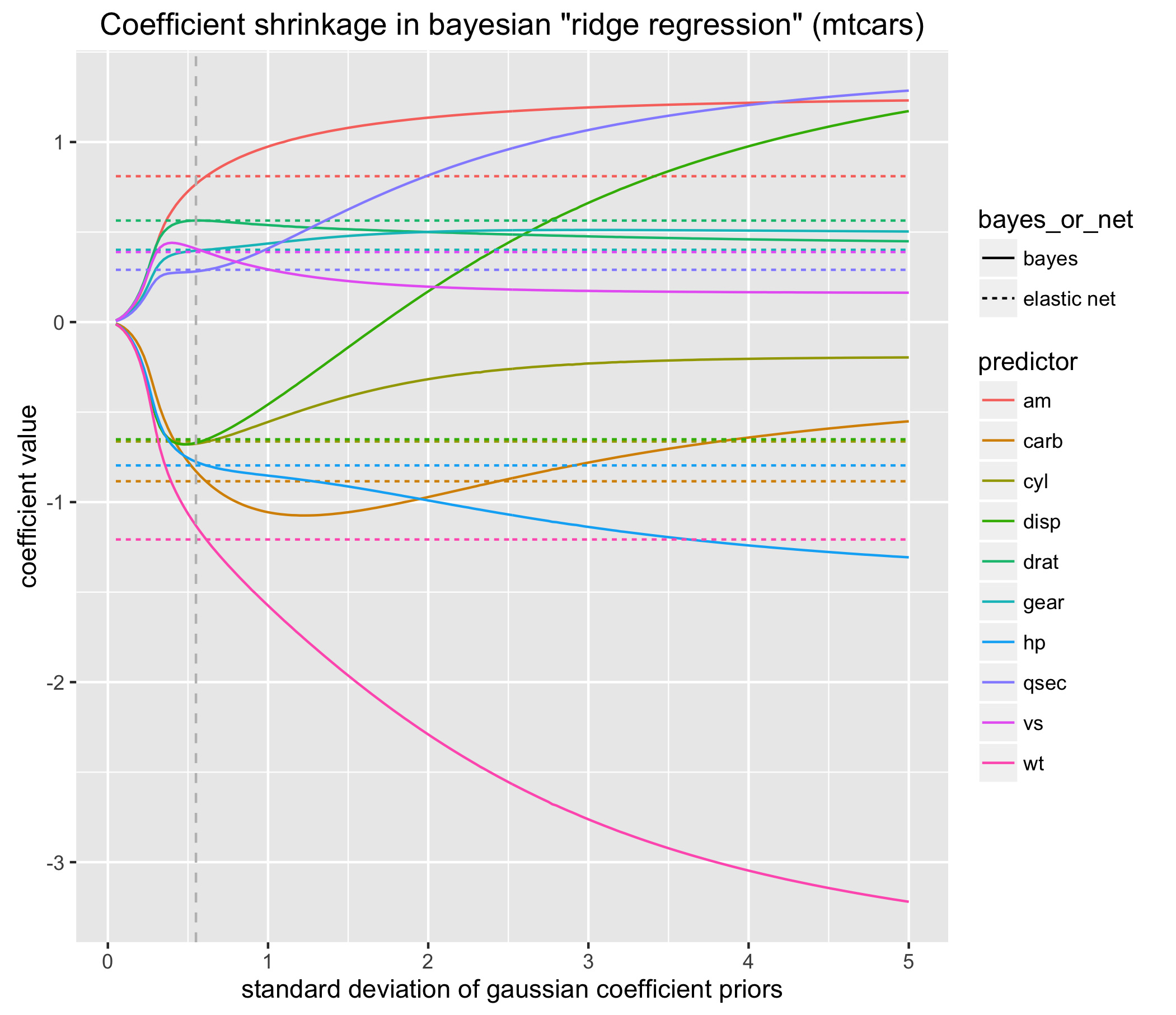
These results are pretty exciting! (if you’re the type to not get invited to parties). Notice that, at the highest performing prior width, the coefficients of the bayesian approach and the glmnet approach are virtually identical.
Sooooo, not only did the bayesian variety produce an equivalently generalizable model (as evinced by equivalent cross-validated MSEs) but also yielded a vector of beta coefficient estimates nearly identical to those estimated by glmnet. This suggests that both the bayesian approach and glmnet‘s approach, using different methods, regularize the model via the same underlying mechanism.
A drawback of the bayesian approach is that its solution takes many orders of magnitude more time to arrive at. Two advantages of the Bayesian approach are (a) the ability to study the posterior distributions of the coefficient estimates and ease of interpretation that they allows, and (b) the enhanced flexibility in model design and the ease by which you can, for example, swap out likelihood functions or construct more complicated hierarchal models.
If you are even the least bit interested in this, I urge you to look at the code (in this git repository) because (a) I worked really hard on it and, (b) it demonstrates cool use of meta-programming, parallelization, and progress bars… if I do say so myself :)