Abstract: I did some computer-y stuff to construct a personal Spanish text corpus and create a Spanish verb study guide specifically tailored to the linguistic variety of Spanish I intend to consume and produce. It worked fairly well. It also revealed a (in some small way) generalizable depiction of the relative frequencies of Spanish verb tenses and moods. This technique may prove to be extremely beneficial to Spanish-language pedagogy. If you’re uninterested in my motivations or procedure, you can skip to the section labeled “results”.
As regular readers of this blog may be aware, one of my favorite activities is marshaling the skills that I use as a computational scientist to study the humanities. For example, in a previous post, we saw how principles from phylogenetic systematics helped textual critics reconstruct the original manuscript for “The Canterbury Tales”; in another, we deployed techniques first used to study physics to the end of fooling vineyards into retweeting fake, computer-generated wine reviews.
For this post, I used both tools from computational linguistics and some good-old-fashioned data wrangling (web-scraping, parsing texts, etc…) to create a custom-fit Spanish verb study guide.
The problems
Problem #1
Although foreign language immersion is the almost certainly the best learning path for most types of foreign language learners, no reasonable student without an lavish budget for traveling can expect to get by without having to do some rote memorization. In the context of Spanish verbs, this either means unguided memorization of a dictionary or consultation of a list of the most commonly used Spanish verbs. But, even if you could trust that the most-popular-verbs list was compiled in a principled manner, there are vast regional and sub-culture-specific variations in verb frequency. For example, the verb coger means “to take” in Spain but in Central America it’s… it’s a… pretty vulgar verb. It stands to reason that there are pretty enormous differences in this verb’s popularity across regions, contexts, and registers. Depending on which region’s dialect you prioritize familiarity with, and depending on how raggle-taggle the people you intend to roll with are—or the media you intend to consume—a one-size-fits-all verb list might let you down.
Problem #2
English isn’t a very inflective language—the tense (or person, mood, aspect, etc…) is largely determined, not through verb conjugation, but via periphrasis, the use of personal pronouns, and other auxiliary words. This is in stark comparison to Spanish, a highly-inflective, relatively synthetic language where the verb’s conjugation betrays its tense, person, mood, and aspect—all in one word! This linguistic elegance is a learning obstacle, since one verb might be written in a little under 60 different ways (6 persons * (4 tenses in the indicative mood + 3 tenses in the subjunctive mood + 1 imperative mood)). This pedagogical nightmare is partially allayed by careful prioritization of some tenses and moods, over others—at least initially. For example, a Spanish-language learner almost always learns the commonly-used and versatile present indicative tense first. But beyond the next few obvious choices, the order in which these tenses should be prioritized is not clear and (probably) dependent on how and where you expect to use and consume the language. Further complicating things, there are entire persons (here’s looking to you, vosotros) that are very uncommon in most Spanish-speaking countries.
The solution
The solution to this problem is to create a personal corpus of Spanish text, containing examples of the types of text you expect to consume and produce. Then, the verbs need to be identified, have their mood, tense, and person recorded, and converted into infinitive form (for frequency tabulation). The relative frequencies of the persons, mood, and tenses—as well as the frequencies of the verbs (in infinitive form)—will inform the creation of a Spanish verb study guide specifically catered to type of linguistic variety the learner intends to employ. Whether the learner’s primary interest in learning Spanish is to be able to bond with a new family member over their love of Mexican telenovelas or to read and understand Don Quixote in its entirety, this approach will hasten the learner’s sense of accomplishment with respect to cookie-cutter verb study guides, increase learner satisfaction, and increase the likelihood of the learner actually achieving language mastery. I mean, as a learner myself, I would be discouraged if I felt like the main payoff of studying Spanish is to read and understand books that are very obviously juvenile or primary meant for pedagogical purposes. I want to read Márquez and I want to read him now!
The corpus
For my particular corpus, I chose a whole mess of books (most of which I’ve read—and loved—in English) that I’m interested in reading in the original language. These include Rayuelas and Final De Juego by Julio Cortázar (my favorite short story writer), Cien Años De Soledad by Gabriel García Márquez (generally considered to be a masterpiece), Darios de Motocicleta by Che Guevara, Ficciones by Jorge Luis Borges, and La Cuidad De Las Bestias by Isabel Allende. These texts were obtained electronically—legitimately!—and I used various ad-hoc regexes to remove formatting and conversion-from-PDF-to-text) artifacts.
My interest in Spanish isn’t only for consuming literature, though; I wanted to include other sources of text, like movie scripts (I planned on Lo Que le Pasó a Santiago, generally considered to be one of the best Puerto Rican films), but I couldn’t find the script online. I also wanted to include the lyrics to my favorite Spanish-language bands (Soda Stereo, El Ultimo Vecíno, Décima Víctima, Caifenes, Shakira, Millie Quezada, …) but the tool I used to identify the verbs in the corpus often choked on these texts. Why, you ask?…
Parts-of-speech tagging
references are at the bottom of the post
Parts-of-speech tagging (hereafter, ‘POS tagging’) is when you go through a text and, for each word, identify the which part of speech (verb, noun, adjective, etc…) the word functions as.
This is a non-trivial task because the same word can function as different parts-of-speech depending on the context. Take the following sentence, for example, which is an expanded and modified version of a sentence that is used as an example in this video
Fruit flies like bananas
So, taken individually, all words in this sentence can function as multiple parts of speech. Take “like” for instance; it can be a noun (“my status got mad likes“), a verb (“I like your status“), a quotative (“I was like, ‘I enjoyed your status‘“), conjunction (_“I updated my status like the world depended on it_”), a preposition (“I wrote my status like Nathaniel Hawthorne“). Depending on how colloquial the text in question is, “like” can even be used as a discourse marker (“I’m, like, scared of ghosts, Scoob“). As a standalone word, “like” can serve the purpose of 6 different parts of speech.
But even looking at the entire sentence as a whole, the parts-of-speech for each word is ambiguous.
Concretely, the sentence can be interpreted as (a) “fruit flies (noun) like (verb) bananas (noun)”, (b) “fruit (noun) flies (verb) like (preposition) bananas (noun) [do]”, or even (c) “fruit (noun) flies (verb) like (conjunction(?)) bananas (adjective)”—using the colloquial meaning of the word bananas meaning “crazy”.
Note that the POS tag for one word is conditional on the POS tags of other words: whether flies is a noun or a verb affects whether bananas is interpretable as a adjective.
Because this task isn’t easy, this job used to be left to humans to perform. Now, various techniques allow for this to be done programmatically to a high degree of accuracy. We’ll go through a few of them, ending with the sophisticated method employed by the POS tagger that we will be using, the Stanford Parts-of-speech tagger.
Unigram tagging
A training corpus with the POS tags for each word is read and, for each unique word, the number of times it is used as one of the various parts of speech is tallied. When a word is encountered in untagged text, the tagger chooses the part-of-speech that the word is most commonly used as in the training text. If the word encountered was not in the training text at all, it defaults to a noun. Somehow, this context-free elementary method can yield accuracies of 90%-94% (Brill & Wu, 1998). When Brill and Wu used this method with/on the famous Penn Treebank Wall Street Journal corpus with a 80%/20% training/testing split, it achieved 93.3% accuracy.
n-gram tagging
Using an n-gram model, the tag of a particular word is assumed to be conditionally dependent on the tag of the preceding n-1 words. For example, in a bigram model, the tag of the current word is guessed from the current word, and the tag of the previous word. A trigram model uses tag information from the previous two words, in concert with the conditional probability of a particular tag given a certain word. The unigram tagger is a special case of the _n_-gram tagger where n is 1. It’s not hard to see that _n_-gram tagging will offer an enormous accuracy improvement.
If this reminds you of the Markov chains that we made use of in the previous post on computer-generating wine reviews, then you have a good eye. N-gram tagging is a type of Hidden Markov Model (HMM). What makes HMMs different than simple Markov models is that the states themselves (the POS tags) are not directly observable; the observable portion of each state are the actual words—and the words are only a probabilistic function of the state.
In addition to testing a unigram model, Brill and Wu also tested this technique’s ability on the WSJ corpus. In particular, they used a trigram tagger—with a twist. Weischedel, Ralph, et al (1993) noted that the suffix of a word (-ed, -s, -ing, -ion, -ly, etc…) strongly influenced the probability that the word served as a particular part of speech. When this information was wielded to help classify unknown words, it greatly improved accuracy outcomes. When Brill and Wu used this method with a trigram tagger against the WSJ corpus, the technique yielded an 96.4% accuracy rate.
Maximum Entropy models
Maximum Entropy models are a lot like—insofar as they are equivalent to—multinomial logistic regression models that attempt to model the probability of a given tag class given various predictor variables, or features. Maximum entropy models can use features such as the current word, the previous word, the previous word’s tag, etc…—like would a HMM—but also features like whether the word contains a number, whether the word is capitalized, etc… An optimization algorithm called Generalized Iterative Scaling selects the feature weights that maximize the likelihood function.
Ratnaparkhi (1996) tested a straightforward maximum entropy model on the WSJ corpus and noted that it yielded an accuracy of 96.6%. Four years after that, Toutanova et al. (2000) published a paper in which they show that by adding additional features like whether the word is capitalized and in the middle of a sentence and non-local features that look 8 words back for a modal verb (for disambiguating base form verbs and non-3rd person singular present verbs) they can achieve a WSJ accuracy of 96.8%. This is the benefit of the Maximum Entropy model approach—you can arbitrarily add features (within reason) without necessarily knowing how those features contribute the the probabilities of tag outputs.
Three years after that, Toutanova et al. (2003) achieved a 97.2% accuracy rate on the WSJ corpus by (a) adding features for the words following the word currently being tagged, and (b) using regularization to combat overfitting as a result of using many features—many of which probably only weakly contribute information of the probability of the current word’s tag class. Their regularization technique involved placing a zero-centered Gaussian prior on the feature weights and is mathematically tantamount to the L2 regularization that we saw in this previous blog post. This state-of-the-art tagger is the one on which the Stanford tagger we use is based.
There is another famous type of POS tagger called Transformation-Based tagger. In contrast to all the others that were mentioned above, this is not a probabilistic/stochastic model and is, instead, based on rules and knowledge. I won’t describe it here because it’s very different and this post is already too long but I should mention that it can score a 96.6% on the on WSJ corpus (Brill et al., 1998).
The procedure
These steps assume a POSIX compliant system and some command-line proficiency
The filenames are links and you can find a repo with all the code here
- Downloaded full version of the Stanford Parts-of-speech tagger
- Ran the tagger on the text, put each tag on a separate line, and filtered for verbs only. The parts-of-speech were identified using this tagset. As you can see, the verbs all start with the letter “v”. This can be achieved by the following incantation:
1 | ./stanford-postagger.sh models/spanish.tagger THE_BOOK.txt perl -pe 's/ /\\n/g' grep '_v' > tmp |
If this causes you problems, you might want to try to give the tagger (which runs in multicore!) more memory; try adding -Xmx2048M as a argument in the java command in ./stanford-postagger.sh—this will give it 2GBs to work with.
- For each work, I ran this.py on it, which parsed the stanford tag and made it in nice tab delimited format:
1 | ./stanford-output-to-nice-tsv.py < tmp > ./output-verbs/THE_BOOK.txt |
- Catted all of them together into all.txt–a monstrous text file with 84,437 words that the tagger interpreted as verbs:
1 | cat rayuelas.txt final-de-juego.txt darios-de-motocicleta.txt cien-anos-de-soledad.txt ficciones.txt la-cuidad-de-las-bestias.txt > all.txt |
Now we need to get the infinitives, but in order to prioritize which we should get the infinitives for, and not have to repeat conjugated verbs, we need to get the uniques…
- So I ran
1 | cat all.txt perl -pe 's/(.+?)\\t.\*/\\1/g' > all-verbs.txt |
to get a list of only verbs (no mood or tense)
- I wanted to get a list of unique verbs sorted by the number of occurrences; this would normally be a job for the
sort uniq -c. Desafortunademente, this command fails. It turns out that unicode can represent (for example) habría in at least two different ways. For this reason, we have to use the python script process-all-verbs.py which uses theunicodedatamodule to normalize the verbs and then count them.
1 | ./process-all-verbs.py tee all-verbs-count.txt |
Ok, now were ready to get infinitive forms for these verbs. We are going to do this by programmatically making request to translate the word to the (excellent) website Span¡shD!ct.com. What we want can be extracted from the returned HTML via CSS selectors.
- get-infinitives.py goes through each line of all-verbs-count.txt and constructs the url to query the website with. It then uses the CSS selector “.mismatch” for information about the verb.
In the best case scenario, it says something like “___“ is the ____ form of _____ in the ____“. Sometimes, there’s more than one possible person or tense so it says “____ represents different conjugations of the verb _____“
In either case, we get the infinitive. If it fails, we record it and move on. It waits between 1 and 2 seconds between each verb. After every 20, it dumps the JSON so that in case something bad happens I could just load the intermediate results and restart.
- You can see that the SpanishDict infinitive conversion systematically failed for certain words. For example, it interpreted inflected verbs like he, dice, and era as English words to translate, not Spanish words to provide information for. In other cases, it interpreted a verb’s past participle (aburrir -> aburrido (“to bore”)) as an adjective (“boring”). I manually filled in many of the ones that failed using equal parts regex and black magic. This went into finished-supplemented.json.
- Finally, we need to inner join all.txt
to the information infinished-supplemented.json. The combine.py script does this:
1 | ./combine.py tee tagged-plus-infinitives.txt [/code] |
The tab-delimited tagged-plus-infinitives.txt in now ready to be consumed for analysis.
Some numbers
- Rayuelas - 203,197 words - 29,882 verbs Final de juego - 54,303 words - 8,160 verbs Darios de Motocicleta - 53,804 words - 6,557 verbs Cien Años de Soledad - 15,4381 words - 20,987 verbs Ficciones - 48,845 words - 5,769 verbs La Cuidad De Las Bestias - 94,075 words - 13,082 verbs
- There were 84,437 words that the tagger identified as verbs in all.
- There were 13,972 unique conjugated verbs.
- After the first try with SpanishDict, for only 6,852 verbs did we have the infinitives. This greatly increased with the black magic alluded to in the previous section.
- I went from 84,437 to 71,378 verbs when I inner joined with the verbs that I was able to find infinitives for.
The results
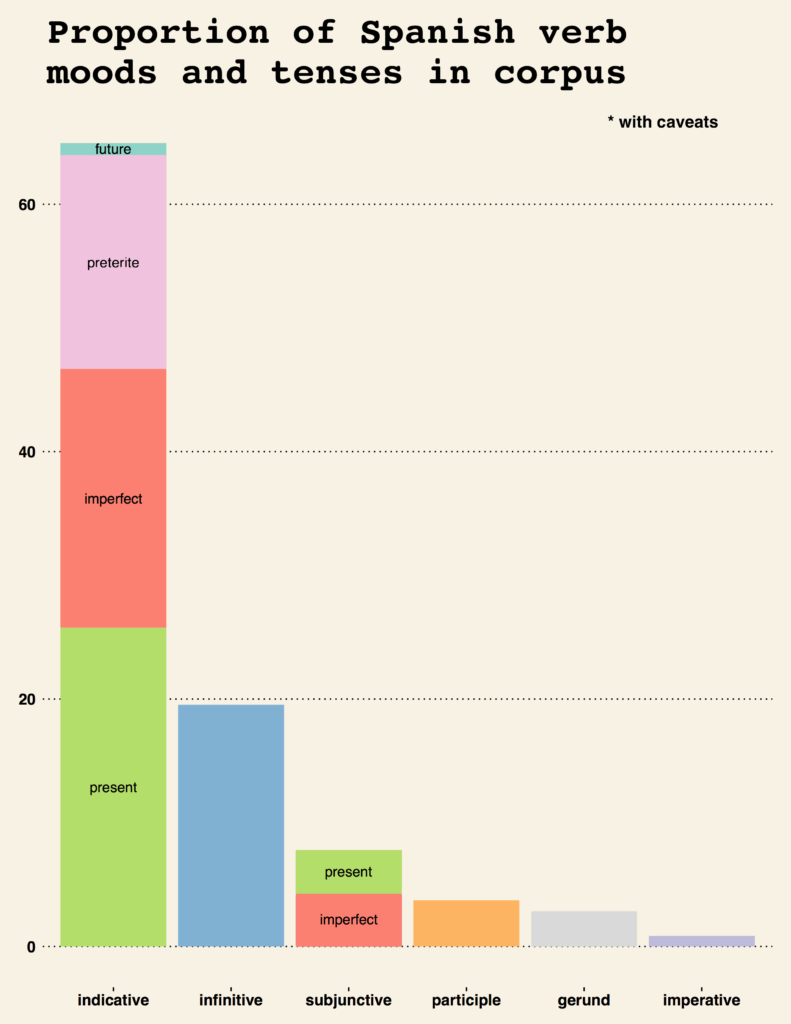
Proportion of Spanish verb moods and tenses in corpus
The results were rather fascinating.
These were the 14 most common conjugated verbs:
| conjugated verb | count | percent |
|---|---|---|
| había | 2599 | 3.64 |
| era | 2396 | 3.36 |
| es | 2303 | 3.23 |
| dijo | 1763 | 2.47 |
| estaba | 1169 | 1.64 |
| fue | 816 | 1.14 |
| ser | 606 | 0.85 |
| habían | 517 | 0.72 |
| hay | 512 | 0.72 |
| tenía | 467 | 0.65 |
(you can see the full spreadsheet here)
With this information alone, this whole endeavor was worth it. Sure, most of the verbs in this list aren’t that much of a surprise, but there are two pieces of information that could prove really helpful to me. The first is that 4 verbs in the top 15 are forms of the verb haber (“to have”)—including the very first one, which accounts for 3.6% of all conjugated verbs in the corpus. This is a verb that I was, heretofore, relatively unfamiliar with.
In contrast to tener (which also means “to have”), haber is often used as an auxiliary verb as it would in such english sentences as “I have to go to the dentist”, “I had all but lost it” (past perfect tense), “there is a freeze-up coming”. Because of it’s ubiquitous usage as an auxiliary word (like its being used in all sentences in the perfect mood), I should get more familiar with this verb and its conjugations if I ever hope to read these works of literature.
The second important piece of information for me was that a majority of the verbs in the top 14 were in the imperfect tense (a type of past tense). Now, I think I may have been concentrating too much on the preterite tense (another past tense) in comparison. Next, these were the 14 most common verbs when put into infinitive form:
| infinitive | count | perc |
|---|---|---|
| ser | 8066 | 11.3 |
| haber | 5461 | 7.65 |
| estar | 2746 | 3.85 |
| decir | 2734 | 3.83 |
| tener | 1774 | 2.49 |
| hacer | 1757 | 2.46 |
| ir | 1721 | 2.41 |
| poder | 1614 | 2.26 |
| ver | 1336 | 1.87 |
| dar | 1210 | 1.7 |
(you can see the full spreadsheet here)
To me, there wasn’t really anything unexpected here except for maybe pasar (to happen) and parecer (to seem), which I was, up until this point—relatively unfamiliar with in spite of the fact that they are used in a number of frequently spoken expressions like ¿Que pasó? (“What happened?”) and ¿Que te parece? (~”What do you think?”).
Finally, figure 1 is a plot which depicts the proportions in which each mood and tense occur. The large vertical bars show the relative proportions of each mood (I count the Infinitive, Gerund, and Participle as moods) in descending order; they are Indicative (65%), Infinitive (20%), Subjunctive (4%), Participle (4%), Gerund (3%), and Imperative (1%). Each vertical bar is further broken down by the proportion of each tense within that mood (sorted, with the most frequently used on the bottom. For example, the present tense is the most common tense in the indicative mood and accounts for 26% of all mood/tense pairs. The Infinitive, Participle, and Imperative moods (to the extent that there are actually moods) have only one tense (to the extent that they can be said to have tenses).
These results were most surprising to me; for one, I was (again) reminded that I should probably hold nailing down the imperfect tense with as much or more importance as I do with the preterite tense. Second, I was surprised that usage of the future tense was far eclipsed by gerund, participle, and both subjective tenses—in spite of the fact that I use it quite often in my texts to my friends and my internal monologue. Of course, this—and other insights—may just be artifacts of the particular body of literature I chose for my corpus (see next section).
Limitations:
Although this was a wildly fun project that yielded interesting and extremely practical insights, there are a number of important caveats to be aware of when interpreting these results.
First is a generalizability issue; the results indicate the verb popularity and mood/tense breakdowns for just 6 pieces of Spanish literature. Because of this, the corpus is heavily dominated by the writing style of the included authors—at least some of whom have a very idiosyncratic writing style. Additionally, as with most literature, all of the non-short-stories in my corpus were told in the past tense (usually by a third person omniscient narrator). This past tense bias is very clearly non-representative of everyday spoken Spanish (of course, it was never meant to be representative of that). This problem could have been, at least partially, alleviated via the inclusion of more prosaic Spanish from movie scripts and blogs—if only they POS tagged correctly!!
Speaking of tagging correctly, the second issue is one of the correctness of the POS tags. The best POS taggers (Stanford is certainly one) can, at best, achieve an accuracy of 97%. Although this is an incredible feat of computational linguistics and the product of many many years of research, it is important to put this in the proper perspective. Recall that the rudimentary unigram tagger can achieve a 90%-94% accuracy rate (b) the 97% accuracy rate decreases as the testing corpus diverges in style from the training corpus. Especially because of Cortázar—who (at least in English translations) employs highly unusual sentence structure and often straight-up grammatically-incorrect non-human-parsable sentences—this fact must be kept in mind; unless the Spanish model that comes with Stanford was trained with Surrealist literature (it wasn’t!), tag accuracy will suffer.